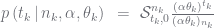“Accurate parameter estimation for Bayesian network classifiers using hierarchical Dirichlet processes”, by François Petitjean, Wray Buntine, Geoffrey I. Webb and Nayyar Zaidi, in Machine Learning, 18th May 2018, DOI 10.1007/s10994-018-5718-0. Available online at Springer Link. To be presented at ECML-PKDD 2018 in Dublin in September, 2018.
Abstract This paper introduces a novel parameter estimation method for the probability tables of Bayesian network classifiers (BNCs), using hierarchical Dirichlet processes (HDPs). The main result of this paper is to show that improved parameter estimation allows BNCs to outperform leading learning methods such as random forest for both 0–1 loss and RMSE, albeit just on categorical datasets. As data assets become larger, entering the hyped world of “big”, efficient accurate classification requires three main elements: (1) classifiers with low bias that can capture the fine-detail of large datasets (2) out-of-core learners that can learn from data without having to hold it all in main memory and (3) models that can classify new data very efficiently. The latest BNCs satisfy these requirements. Their bias can be controlled easily by increasing the number of parents of the nodes in the graph. Their structure can be learned out of core with a limited number of passes over the data. However, as the bias is made lower to accurately model classification tasks, so is the accuracy of their parameters’ estimates, as each parameter is estimated from ever decreasing quantities of data. In this paper, we introduce the use of HDPs for accurate BNC parameter estimation even with lower bias. We conduct an extensive set of experiments on 68 standard datasets and demonstrate that our resulting classifiers perform very competitively with random forest in terms of prediction, while keeping the out-of-core capability and superior classification time.
Keywords Bayesian network · Parameter estimation · Graphical models · Dirichlet 19 processes · Smoothing · Classification
“Leveraging external information in topic modelling”, by He Zhao, Lan Du, Wray Buntine & Gang Liu, in Knowledge and Information Systems, 12th May 2018, DOI 10.1007/s10115-018-1213-y. Available online at Springer Link. This is an update of our ICDM 2017 paper.
Abstract Besides the text content, documents usually come with rich sets of meta-information, such as categories of documents and semantic/syntactic features of words, like those encoded in word embeddings. Incorporating such meta-information directly into the generative process of topic models can improve modelling accuracy and topic quality, especially in the case where the word-occurrence information in the training data is insufficient. In this article, we present a topic model called MetaLDA, which is able to leverage either document or word meta-information, or both of them jointly, in the generative process. With two data augmentation techniques, we can derive an efficient Gibbs sampling algorithm, which benefits from the fully local conjugacy of the model. Moreover, the algorithm is favoured by the sparsity of the meta-information. Extensive experiments on several real-world datasets demonstrate that our model achieves superior performance in terms of both perplexity and topic quality, particularly in handling sparse texts. In addition, our model runs significantly faster than other models using meta-information.
Keywords Latent Dirichlet allocation · Side information · Data augmentation ·
Gibbs sampling
“Experiments with Learning Graphical Models on Text”, by Joan Capdevila, He Zhao, François Petitjean and Wray Buntine, in Behaviormetrika, 8th May 2018, DOI 10.1007/s41237-018-0050-3. Available online at Springer Link. This is work done by Joan Capdevila during his visit to Monash in 2017.
Abstract A rich variety of models are now in use for unsupervised modelling of text documents, and, in particular, a rich variety of graphical models exist, with and without latent variables. To date, there is inadequate understanding about the comparative performance of these, partly because they are subtly different, and they have been proposed and evaluated in different contexts. This paper reports on our experiments with a representative set of state of the art models: chordal graphs, matrix factorisation, and hierarchical latent tree models. For the chordal graphs, we use different scoring functions. For matrix factorisation models, we use different hierarchical priors, asymmetric priors on components. We use Boolean matrix factorisation rather than topic models, so we can do comparable evaluations. The experiments perform a number of evaluations: probability for each document, omni-directional prediction which predicts different variables, and anomaly detection. We find that matrix factorisation performed well at anomaly detection but poorly on the prediction task. Chordal graph learning performed the best generally, and probably due to its lower bias, often out-performed hierarchical latent trees.
Keywords Graphical models · Document analysis · Unsupervised learning ·
Matrix factorisation · Latent variables · Evaluation

 that is the mean for a probability vector
that is the mean for a probability vector  . You then have data, a count vector
. You then have data, a count vector  , drawn using a multinomial distribution with mean
, drawn using a multinomial distribution with mean 





 ; can be computed using Gamma functions
; can be computed using Gamma functions
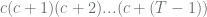 so it corresponds to
so it corresponds to 


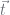 where
where  represents the subset of the count
represents the subset of the count 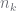 that will be passed up from the
that will be passed up from the  -node to convey information about the data
-node to convey information about the data 
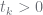 whenever
whenever 

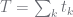

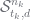 ; and
; and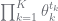 which is a multinomial likelihood. So, as said earlier,
which is a multinomial likelihood. So, as said earlier,  then all the data is passed up, and the likelihood looks like
then all the data is passed up, and the likelihood looks like  , which is what you would get if
, which is what you would get if  .
.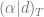 simplifies to
simplifies to  . This small change means that the above formula can be rewritten as:
. This small change means that the above formula can be rewritten as: