
Following on from Lancelot James’ post on the Pitman-Yor process (PYP) I thought I’d follow up with key events from the machine learning perspective, including for the Dirichlet process (DP). My focus is the hierarchical versions, the HPYP and the HDP.
The DP started to appear in the machine learning community to allow “infinite” mixture models in the early 2000’s. Invited talks by Michael Jordan at ACL 2005 and ICML 2005 covers the main use here. This, however, follows similar use in the statistical community. The problem with this is that there are many ways to set up an infinite mixture model or an approximation to one, although the DP is certainly elegant here. So this was no real innovation for statistical machine learning.
The real innovation was the introduction of the hierarchical DP (HDP) with the JASA paper by Teh, Jordan, Beal and Blei appearing in 2006, and a related hierarchical Pitman-Yor language model at ACL 2006 by Yee Whye Teh. There are many tutorials on this, but an early tutorial by Teh covers the range from DP to HDP, “A Tutorial on Dirichlet Processes and Hierarchical Dirichlet Processes” and starts discussing the HDP about slide 37. It is the “Chinese restaurant franchise,” a hierarchical set of Chinese restaurants, that describes the idea. Note, however, we never use these interpretations in practice because they require dynamic memory.
These early papers went beyond the notion of “infinite mixture model” to the notion of an “hierarchical prior”. I cover this in my tutorial slides discussing n-grams. I consider the hierarchical Pitman-Yor language model to be one of the most important developments in statistical machine learning and a stroke of genius. These were mostly based on algorithms using the Chinese restaurant franchise, based on the Chinese restaurant process (CRP) which is a distribution got by marginalising the probability vectors out of the DP/PYP.
Following this was a period of enrichment as various extensions of CRPs were considered, culminating in the Graphical Pitman-Yor Process developed by Wood and Teh, 2009. CRPs continue to be used extensively in various areas of machine learning, particularly in topic models and natural language processing. The standard Gibbs algorithms, however, are fairly slow and require dynamic memory, so do not scale well.
Variational algorithms were developed for the DP, and consequently the PYP, using the stick-breaking representation presented by Ishwaran and James in 2001, see Lancelot James’ comments. The first of these was by Blei and Jordan 2004, and subsequently variations for many different problems were developed.
Perhaps the most innovative use of the hierarchical Pitman-Yor process is the Adaptor Grammar by Johnson, Griffiths and Goldwater in 2006. Todate, these have been under-utilised, most likely because of the difficulty of implementation. However, I would strongly recommend any student of the HPYPs to study this work carefully because it shows both a deep understanding of HPYPs and of grammars themselves.
Our work here started appearing in 2011, well after the main innovations. Our contribution is to develop efficient block Gibbs samplers for the HYP and the more general GPYP that require no dynamic memory. These are not only significantly faster, they also result in significantly superior estimates. For our non-parametric topic model, we even did a simple multi-core implementation.
- An introduction to our methods are in Lan Du‘s thesis chapters 1 and 2. We’re still working on a good publication but the general background theory appears in our technical report “A Bayesian View of the Poisson-Dirichlet Process,” by Buntine and Hutter.
- Our samplers are a collapsed version of the corresponding CRP samplers requiring no dynamic memory so are more efficient, require less memory, and usually converge to better estimates.
- An algorithm for the GPYP case appears in Lan Du‘s PhD thesis.
- An algorithm for splitting nodes in a HPYP is in our NAACL 2013 paper (see Du, Buntine and Johnson).
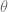 from its parent
from its parent 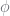 as follows:
as follows: (1)
(1) are the parameters of the PYP called discount and
are the parameters of the PYP called discount and  and
and  . The
. The  are magical auxiliary (latent) counts that make the PYP samplers work efficiently. They are, importantly, constrained by their corresponding counts, and the counts are computed up from the leaves up (using
are magical auxiliary (latent) counts that make the PYP samplers work efficiently. They are, importantly, constrained by their corresponding counts, and the counts are computed up from the leaves up (using  to denote
to denote  ). The
). The 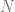 s and
s and  s are totals. These relationships are summarised in the table below.
s are totals. These relationships are summarised in the table below.
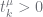 whenever
whenever 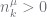



 . This is not the case with us. Here the non-leaf nodes represent priors on the leaf nodes, they do not represent alternative models. PYP theory tells us how to make inference about these priors.
. This is not the case with us. Here the non-leaf nodes represent priors on the leaf nodes, they do not represent alternative models. PYP theory tells us how to make inference about these priors.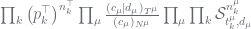 (2)
(2)
 ; can be computed using Gamma functions
; can be computed using Gamma functions
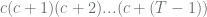 so it corresponds to
so it corresponds to 

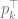

 and counts
and counts 
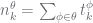

 does not exist. For
does not exist. For 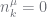
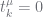

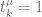


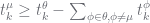
 (3)
(3)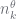 ,
,  and
and  . When
. When  (4)
(4) do:
do: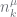 is large. We overcome this by constraining
is large. We overcome this by constraining  at the leaves, propagate these to the
at the leaves, propagate these to the 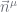 at the next level, estimate
at the next level, estimate 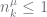 then
then
 then # the PYP case
then # the PYP case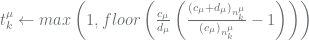

 is the digamma function
is the digamma function
 and
and  can potentially take on many values, and it is expensive to compute the generalized Stirling numbers
can potentially take on many values, and it is expensive to compute the generalized Stirling numbers 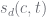 .
. , by smoothing the observed data
, by smoothing the observed data  . The formula used by Teh is as follows:
. The formula used by Teh is as follows: .
. counts
counts  . The more or less counts you pass up the stronger or weaker you are making the message.
. The more or less counts you pass up the stronger or weaker you are making the message. at leaf nodes
at leaf nodes 

