
If you’re familiar with the Dirichlet distribution as the workhorse for discrete Bayesian modelling, then you should know about the Dirichlet-multinomial. This is what happens when you combine a Dirichlet with a multinomial and integrate/marginalise out the common probability vector.
Graphically, you have a probability vector 


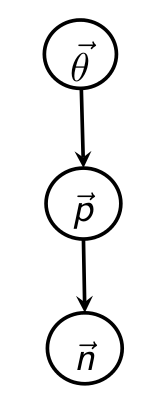
The standard formulation is to have:

Manipulating this, we get the distribution for the Dirichlet-multinomial:



Now we will rewrite this into the Pochhammer symbol notation we use for Pitman-Yor marginals,
 |
is the Pochhammer symbol (a generalised version is used, and a different notation) which is a form of rising factorial so its given by  ; can be computed using Gamma functions ; can be computed using Gamma functions |
 |
(special case) a related rising factorial given by 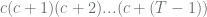 so it corresponds to so it corresponds to  |
The Beta functions simplify to yield the Dirichlet-multinomial in Pochhammer symbol notation:

Now lets do the same with the Pitman-Yor process (PYP).

The derivation of the combination is more detailed but is found in the Buntine Hutter Arxiv report or my tutorials. For this, you have to introduce a new latent vector 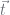

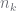

| constraint |  |
| constraint | 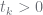 whenever whenever  |
| total |  |
| total | 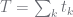 |
With these, we get the PYP-multinomial in Pochhammer symbol notation:

You can see the three main differences. With the PYP:
- the terms in
- you now have to work with the generalised Stirling numbers
; and
- you have to introduce the new latent vector
The key thing is that 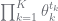



If we use a Dirichlet process (DP) rather than a PYP, the only simplification is that 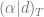


This has quite broad implications as the
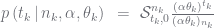
The penalty for using the PYP or DP is that you now have to work with the generalised Stirling numbers and the latent vector
Now one final note, this isn’t how we implement these. Sampling the full range of

