This Sydney 2015 MLSS summer school is organised by Edwin Bonilla and held in Sydney Feb 16-25th. My tutorial is titled “Models for Probability/Discrete Vectors with Bayesian Non-parametric Methods.” My final version of the slides is here in PDF.
Archive for February, 2015

How many clusters?
February 20, 2015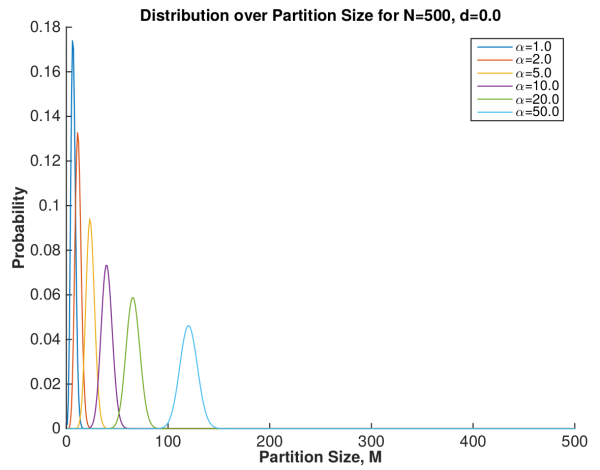
Sometimes people think that a Dirichlet Process (DP) can be used to pick the “right number of clusters”. The following plots done by Monash Matlab whiz Mark Carman show that this has to be done very carefully.
Given 



where 
So fixing a given concentration parameter means roughly fixing the number of clusters, which increases as the sample size grows. So with a fixed concentration parameter you cannot really “estimate” the right number of clusters … roughly you are fixing the value ahead of time when setting the concentration.
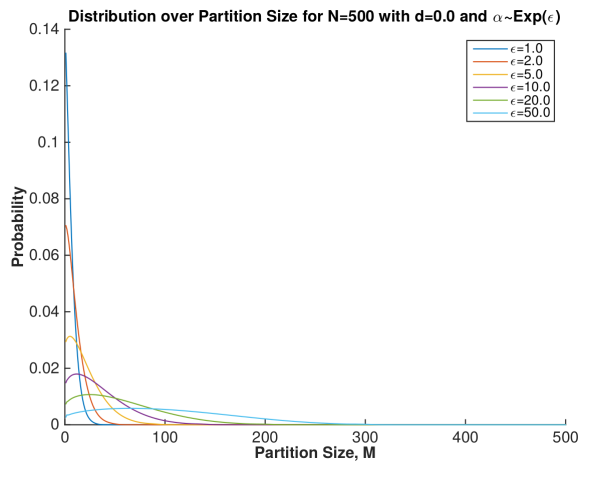
Mark’s second plot shows what we do to overcome this. We have to estimate the concentration parameter as well. So if we put a prior distribution, an Exponential with parameter 
In implementation, this means we estimate the concentration
Video of a Lecture
February 20, 2015The talk I gave at JSI (Jozef Stefan Institute in Ljublana) on 14th Jan 2015 was recorded. The group here, with Dunja Mladenić and Marko Grobelnik, are expert in areas like Data Science and Text Mining, but they’re not into Bayesian non-parametrics, so in this version of the talk I mostly avoided the statistical details and talked more about what we did and why. The talk is up on Video Lectures. The original PDF of the EU talk sequence was on this post.
Lancelot James’ general theory for IBPs
February 9, 2015When I visited Hong Kong last December, Lancelot James gave me a tutorial on his generalised theory of Indian Buffet Processes, which includes all sorts of interesting extensions that are starting to appear in the machine learning community.
The theory is written up in his recent Arxiv report, “Poisson Latent Feature Calculus for Generalized Indian Buffet Processes.” I’m a big fan of Poisson processes, so its good to see the general theory written up, including a thorough posterior analysis. In my recent tutorial (given at Aalto) I’ve included a simplified version of this with the key marginal posterior for a few well known cases. Piyush Rai from Duke also has great summary slides as part of Lawrence Carin’s reading group at Duke.
Within this framework, you can now handle variations like the Beta-negative-Binomial Process of Mingyuan Zhou and colleagues presented at AI Stats 2012 (Arxiv version here), for which many different variations can be developed.
I’ve presented the general case as an application of improper priors because the Poisson process theory in this case is mostly just formalising their use for developing “infinite parameter vectors”. Lancelot uses his Poisson Process Partition Calculus to develop a clean, general theory. For me it was interesting to see that his results also apply to multivariate and auxiliary parameter vectors:
- an infinite vector of Gamma scales
created using a Gamma process can have an auxiliary vector of Gamma shapes
sampled pointwise, so
is associated with
- most of the scales are infinitesimal
- most of the shapes are not infinitesimal
- an infinite set of
-dimensional multinomial’s can be created where the first
dimensions are generated using a Dirichlet style Poisson rate:
- most of the multinomials will have infinitesimal values in the first
- the Beta process corresponds to the case where
- most of the multinomials will have infinitesimal values in the first



