
Sometimes people think that a Dirichlet Process (DP) can be used to pick the “right number of clusters”. The following plots done by Monash Matlab whiz Mark Carman show that this has to be done very carefully.
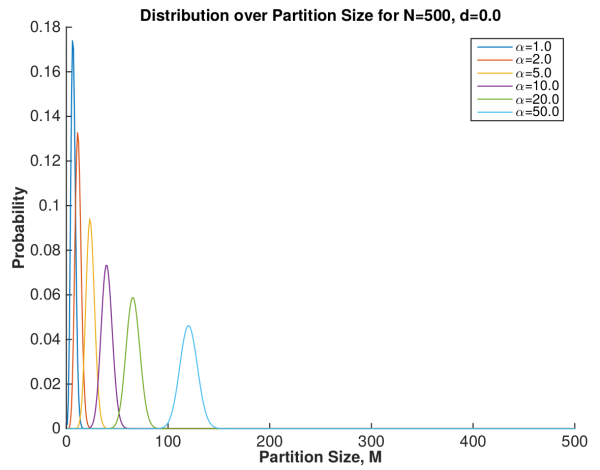
Given  samples, Mark’s first plot shows the expected number of clusters,
samples, Mark’s first plot shows the expected number of clusters,  , that one would get with a DP using concentration parameter
, that one would get with a DP using concentration parameter  . The thing to notice is that the number of clusters is moderately well determined by the concentration parameter. In fact the mean (expected value) of is given by:
. The thing to notice is that the number of clusters is moderately well determined by the concentration parameter. In fact the mean (expected value) of is given by:

where  is the digamma function; for details see the ArXiv report by Marcus Hutter and I, Section 5.3. Morever, the standard deviation of is approximately the square root of the mean (for larger concentrations).
is the digamma function; for details see the ArXiv report by Marcus Hutter and I, Section 5.3. Morever, the standard deviation of is approximately the square root of the mean (for larger concentrations).
So fixing a given concentration parameter means roughly fixing the number of clusters, which increases as the sample size grows. So with a fixed concentration parameter you cannot really “estimate” the right number of clusters … roughly you are fixing the value ahead of time when setting the concentration.

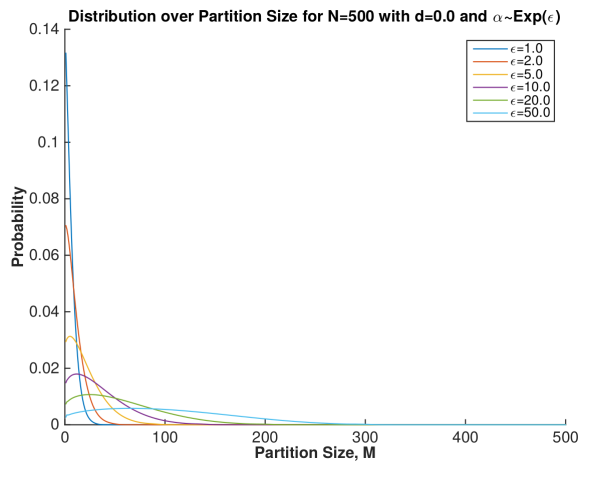
Mark’s second plot shows what we do to overcome this. We have to estimate the concentration parameter as well. So if we put a prior distribution, an Exponential with parameter  , on the concentration, we now smear out the previous plots. So now we show plots for different values of . As you can see, these plots have a much higher variance, which is what you want. With a given , you are still determining the broad range of the number of clusters, but you have a lot more latitude.
, on the concentration, we now smear out the previous plots. So now we show plots for different values of . As you can see, these plots have a much higher variance, which is what you want. With a given , you are still determining the broad range of the number of clusters, but you have a lot more latitude.
In implementation, this means we estimate the concentration (usually) by sampling it. If we use Chinese restaurant processes, there is a simple auxiliary variable sampling formula for the concentration (presented in the original HDP paper by Teh et al.). If we use our blocked table indicator sampling, the posterior on the concentration is log concave so we can use either slice sampling or adaptive rejection sampling (ARS). The implementation is moderately simple, and it works well. However, it does mean now your algorithm will expend more time as it has to try and find the right concentration as well.



Leave a comment