
Training a Pitman-Yor process tree with observed data at the leaves (part 2)
November 13, 2014So here is a recap of the previous post:
A simple problem with hierarchical Pitman-Yor processes (PYPs) or Dirichlet processes (DP) is where you have a hierarchy of probability vectors and data only at the leaf nodes. The task is to estimate the probabilities at the leaf nodes. The hierarchy is used to allow sharing across children …
We have a tree of nodes which have probability vectors. The formula used estimates a probability for node 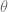
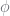

In this, the pair 





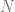

| constraint |  |
| constraint | 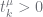 whenever whenever 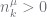 |
| propagating counts |  |
| total |  |
| total |  |
It is important to note here how the counts propagate upwards. In some smoothing algorithms, propagation is 
Now the theory of this configuration appears in many places but Marcus Hutter and I review it in Section 8 of an ArXiv paper, and its worked through for this case in my recent tutorial in the section “Working the n-gram Model”. The posterior distribution for the case with data at the leaf nodes is given by:
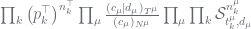
There are a lot of new terms here so let us review them:
 |
is the Pochhammer symbol (a generalised version is used, and a different notation) which is a form of rising factorial so its given by  ; can be computed using Gamma functions ; can be computed using Gamma functions |
 |
a related rising factorial given by 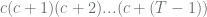 so it corresponds to so it corresponds to  |
 |
the root node of the hierarchy |
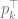 |
the initial/prior probability of the k-th outcome at the root |
 |
a generalised Stirling number of the second kind for discount  and counts and counts  |
Background theory for the Stirling number is reviewed in Section 5.2 of the ArXiv paper, and developed many decades ago by mathematicians and statisticians. We have C and Java libraries for this, for instance the C version is on MLOSS so its O(1) to evaluate, usually.
Now to turn this into a Gibbs sampler, we have to isolate the terms for each
| constraint | |
| constraint | whenever |
| propagating counts | 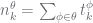 |
| propagating counts |  |
The propagating constraints do not apply when 
when 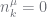 |
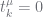 |
when  |
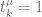 |
when  |
 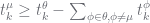 |
The terms in Equation (2) involving

where note that 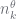



The Gibbs sampler for the hierarchical model becomes as follows:
Gibbs sampler
For each node
for each outcome
do:
sample
endfor
endfor
As noted by Teh, this can result in a very large range for 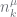
Moreover, we can initialise 
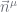
Initialisation
for each level, starting at the bottom do:
for each node
for each outcome
if
then
elseif
then # the PYP case
else # the DP case
#
is the digamma function
endif
endfor
endfor
for each node
endfor
endfor

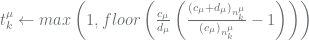


This represents a moderately efficient sampler for the hierarchical model. To make this work efficiently you need to:
- set up the data structures so the various counts, totals and parent nodes can be traversed and accessed quickly;
- set up the sampling so leaf nodes and parents where
- but more importantly, we also need to sample the discounts and concentrations.
Note sampling the discounts and concentrations is the most expensive part of the operation because each time you change them the counts


[…] We will look at the first of these two tasks next. […]