
Training a Pitman-Yor process tree with observed data at the leaves (part 1)
November 12, 2014A simple problem with hierarchical Pitman-Yor processes (PYPs) or Dirichlet processes (DP) is where you have a hierarchy of probability vectors and data only at the leaf nodes. The task is to estimate the probabilities at the leaf nodes. The hierarchy is used to allow sharing across children without resorting to Bayesian model averaging as I did for decision trees (of the Ross Quinlan variety) in my 1992 PhD thesis (journal article here) and done for n-grams with the famous Context Tree Weighting compression method.
The technique used here is somewhat similar to Katz’s back-off smoothing for n-grams but the discounts and back-off weight are estimated differently. Yeh Whye Teh created this model originally, and it is published in an ACL 2006 paper, though the real theory is buried in an NUS technical report (yes, one of those amazing unpublished manuscripts). However, his sampler is not very good, so the purpose of this note is to explain a better algorithm. The error in his logic is exposed in the following quote (page 16 of the amazing NUS manuscript):
However each iteration is computationally intensive as each 

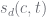
We use simple approximations and caching to overcome these problems. His technique, however, has generated a lot of interest and a lot of papers use it. But the new sampler/estimate is a lot faster, gives substantially better predictive results, and requires no dynamic memory. Note that when the data at the leaves is also latent, such as with clustering, topic models, or HMMs, then completely different methods are needed to enable faster mixing. This note is only about the simplest case where the data at the leaves is observed.
The basic task is we want to estimate a probability of the 
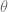

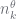
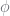


In this, the pair 


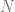





For discount of
If the data is at the leaf nodes, where do the counts 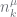



But what then are the 
The 
The idea is that if we expect the probability vector at 
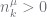
PYP theory and sampling has a property shared by many other species sampling distributions that this just all works. But there is some effort in sampling the 
This Equation (1) is a recursive formula. The task of estimating probabilities is now reduced to:
- Build the tree of nodes and populate the data in counts
at leaf nodes
- Run some algorithm to estimate the
for non-leaf nodes
- Estimate the probabilities from the root node down using Equation (1).
So the whole procedure for probability estimate is very simple, except for the two missing bits:
- How do you estimate the
- How do you estimate the discount and concentration parameters? By the way, we can vary these per node too!
We will look at the first of these two tasks next.


[…] Topical insights into components of prior research and aspects of latent academia « Training a Pitman-Yor process tree with observed data at the leaves (part 1) […]